在实际应用环境中,由于队列、PRP、数据的存储往往在不同的位置,因此完成读取过程的延时也不同,在本开发中,将队列管理与PRP都放置在了近PCIe端存储,因此读取队列与PRP的延时远远小于读取数据的延时。并且当大量不同的读请求交叉处理时,读处理模块的并行处理结构更能够充分利用PCIe的乱序传输能力来提高吞吐量。为了清晰的说明读处理模块对吞吐量的提升,设置如图3.15所示的简单时序样例,样例中PCIe TLP的tag最大为3。
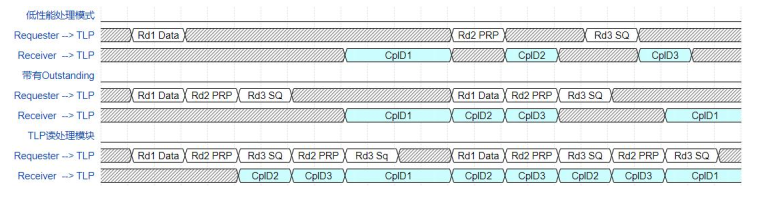
图1 TLP读处理优化时序样例图
在对应图1中第1、2行时序的低性能处理模式下,同一时间只能处理一个读事务,并且不带有outstanding能力,此时从接收到读请求到成功响应所经历的延时将会累积,造成axis_cq请求总线的阻塞。在对应图中第3、4行时序的仅带有outstanding能力的处理模式下,虽然可以连续接收多个读请求处理,但同一时间内只能处理一个事务,仍会由于较大的处理延时导致axis总线存在较多的空闲周期,实际的数据传输效率并不高。在对应图中第5、6行时序的读处理模块处理模式下,利用多个响应处理单元的并行处理能力和发送缓存,先行处理完成的CPLD可以优先发送,紧接着可以处理下一事务B站已给出相关性能的视频,使总线的传输效率和吞吐量明显提高。
- 随机文章
- 热门文章
- 热评文章
- 钢铁行业稳增长方案确定
- 洛轲智能昌敬,又融到70亿
- 1天赚1个亿? 比亚迪发布第三季度财报
- 仅需9.98万元 蓝电E5正式开启限时优惠
- 倍加洁(603059):2023年第一次临时股东大会决议
- 五粮液亮相首届链博会,以“绿色”“和美”链接世界
- 任翠英:标准助力预应力及棒线材高质量发展
- 午间公告|浙江交科下属两家公司预中标合计32.51亿元项目